
Beijing, Shenzhen, and ShanghaiApril 28, 2026 /PRNewswire/ — Today, TermiTech, a company specializing in embodied intelligence brain technology, officially launched the “Goal-conditioned Causal World Model (GCWM1).”
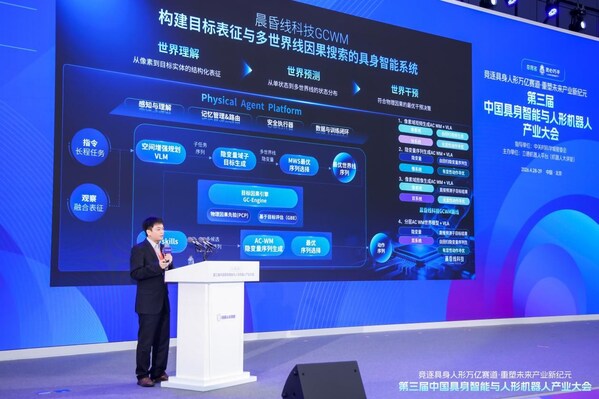
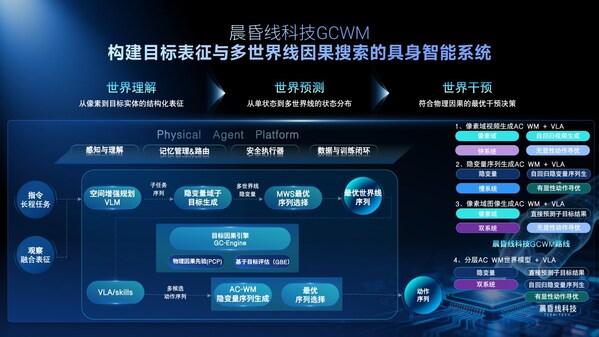
While the industry is still debating whether world models should be “generative” or “representational,” TermiTech has chosen a path closer to the essence of physics: enabling robots to simulate causal chains in the physical world, focusing on goals, within their “minds” before taking action. This provides a distribution of the next state, endowing them with a “deep-thinking” brain that achieves stronger generalization, more accurate state prediction, and higher-certainty autonomous operation.
What does a world model mean for the robotics industry? At this launch event, TermiTech CTO Yu Qing used the recently high-profile “Robot Marathon” to vividly illustrate this point. A year ago, robots stumbled along, with a completion rate of less than 30%, and most participants still required remote control by a navigator throughout the race. Just one year later, nearly 40% of the over 100 participating teams achieved fully autonomous navigation. “Robots have grown a brain,” Yu Qing commented. “This robot marathon is a dual technical report card for the entire industry—while hardware capabilities have advanced by leaps and bounds in a year, the development of the brain is also enabling robots to break free from remote controls, navigate autonomously, and operate independently. The world model is the core part of the robot’s brain.” Breakthroughs on the track also illuminate the next direction: the real scenarios for running are not just on flat tracks, but in ever-changing production workshops, high-precision workstations, and open home environments. In these complex scenarios, robots need to understand the intricate multimodal information of the physical world, vague human instructions, provide accurate predictions of the next state, complete long-term planning based on context, and continuously iterate next-step strategies based on feedback from the physical world. As Yu Qing said: “What we see today is robots gradually breaking free from remote controls, running faster and more steadily. This is a remarkable starting point. We hope that in the future, they will not only run autonomously on tracks but also operate precisely in workshops and factories, interact flexibly in scenic spots and shopping malls, and serve efficiently in communities and homes, truly giving robots a brain, enabling free action and intelligent application.” This is precisely the direction TermiTech is continuously exploring through the GCWM architecture: making every action rooted in a deep understanding of the physical world, making every decision stem from precise predictions based on scenario-specific goals and objective causality, and injecting a truly “thinking brain” into embodied intelligence.
I. From “Getting the Gist” to “Getting the Blueprint”: The Core of Thinking
The first comparison at the launch event came from a seemingly simple instruction: “Find the empty area between the farthest red alarm clock on the table and the fourth object from right to left.”
For traditional models, this is almost a disaster. They can only “get the gist” but cannot understand relative relationships like “farthest,” nor can they directly translate “red alarm clock” into an exact point in physical space. In a production workshop, this means relying on traditional labeling and positioning: once the production line switches to a new machine, new cabin, or new instrument model, all previously accumulated point parameters become invalid. The half-day or even several-day shutdown for parameter adjustment is the most expensive invisible cost in manufacturing. Faced with a new workpiece, it doesn’t require retraining; instead, it uses the same thinking logic to re-map, reasoning through a few steps and going online immediately. This is the rarest capability in flexible manufacturing: robots don’t need to stop for reprogramming; the brain automatically completes scenario-based goal understanding and planning, enabling rapid line changeovers.
The second comparison tests “memory.” The launch event showcased a comparison of finding a teddy bear. While some closed-source models in the industry perform like the legendary goldfish with only seven seconds of memory—forgetting the target halfway through and having to re-identify, repeatedly restarting, wasting a large number of tokens—TermiBrain GCWM1 proposes a causal chain-based reasoning landmark plan mechanism. Once the coordinates of a reference object are marked, the system sets it as a readily queryable marker point, allowing subsequent reasoning to resume from where it left off. The entire reasoning chain is clear and auditable, significantly reducing computational overhead.
Imagine a patrol scenario in a power plant: a robot is performing routine inspections of substation equipment. Suddenly, the system pushes an urgent event requiring immediate attention. Under traditional model management, once the patrol robot leaves the current task site, the records of previously inspected points and unfinished point plans all become a blurry context. When it returns to the original task after handling the emergency, it can no longer find its inspection progress. In contrast, GCWM1 solidifies all verified landmarks and unexecuted landmarks into structured memory nodes, embedded into the causal logic chain. This means a single robot can handle multiple tasks simultaneously without losing any task chain. In real-world urban management, this enables concurrent handling of emergencies and routine patrol tasks.

II. Can Robots Predict the Consequences of Actions Before Acting?
GCWM1 achieves a complete closed loop from world understanding → world prediction → world intervention. Its core philosophy is simple: “A world model should not just be a pixel generator; it must be a physical causality engine.”
Take pouring water as an example. Traditional models would need to exhaustively enumerate all possibilities of pouring water, calculating every droplet’s trajectory and every angle of the cup’s tilt—a bottomless pit of computation. GCWM1’s approach is entirely different. Its Goal-Conditioned Engine (GC-Engine) integrates Physical Causal Priors (PCP) and a Goal-Based Evaluation (GBE) mechanism. Physical Causal Priors directly weave physical laws like gravity, friction, and rigid body constraints into the neural network, while Goal-Based Evaluation enables the model to understand and predict based on task goals, pruning branches that violate common sense and ignoring irrelevant details, thereby significantly reducing computational consumption.
Building on this, GCWM1 further proposes “multi-worldline search”: starting from the underlying constraints of physical priors and task goals, it generates key worldlines causally related to the core goal in parallel within the latent space. Each worldline is clearly labeled with “if this, then that.” The GC-Engine scores the confidence of each worldline based on the goal evaluation module, synthesizing a latent vector representation of the next state. Based on this, it can provide the most likely successful sequence of next actions.
This is the watershed between GCWM1 and previous approaches: leaping from “single-state decision-making” to “multi-state distribution prediction,” giving robots a predictive capability with higher success rates.
Yu Qing gave a vivid example by easily picking up a paper cup filled with water in front of him: during the process of picking up the cup, the brain simulates at least three states—picking it up normally, failing to pick it up, and squeezing it too hard so water spills out. After simulating these three worldlines, most people ultimately decide to try with a smaller force, gradually increase it until the cup is lifted, and then maintain that force to avoid excess. TermiTech’s world model’s “multi-worldline search” is about giving robots this same ability, combining the latent vector distribution of the next state to provide the strategy or combination of strategies most likely to ensure task completion.
This is not about scoring in a lab; it’s about truly thinking through common events in the real physical world.
III. Execution Closed Loop: Atomic Skill Library and Commander-Level Instructions
A powerful brain must be paired with a precise execution system. TermiTech has built a layered, composable atomic skill library, currently encompassing 14 basic skills and 7 advanced skills, including grasping, placing, pushing, distributing, peeling, and pouring. These skills are learned from over 17 scenarios, more than 2,000 trajectories, and over 12,000 skill instance data collected from real machines, and are continuously being expanded and enriched.
Each skill is not a vague action name but a “deterministic function” strictly compiled with parameters, preconditions, and success criteria. Taking the “move” skill as an example, it clearly defines the 2D planar pixel coordinates of the target reference object and motion trajectory constraints: before the robot acts, it not only locks onto “which object” but also locks the target to an exact coordinate in physical space. Meanwhile, the motion trajectory constraint draws a “safe route”—the palm must avoid obstacles, the cup opening must remain upward throughout, and it must decelerate to the force control threshold when approaching the target. This moves robot actions from “imitation by feel” to “precise invocation based on geometric contracts.”
Yu Qing made an apt analogy: “It’s like equipping the robot with a patient and tireless guide. The instruction is no longer a vague ‘Go catch Tang Sanzang!’ Instead, it’s: ‘Listen carefully, I’ll say this only once: First, head towards the East Heavenly Gate, bypassing Guanyin Temple; on the way, don’t eat any mortals, don’t scare the villagers; if you encounter Sun Wukong, lure him away first, don’t confront him head-on; gently bind Tang Sanzang with the Immortal Binding Rope, don’t damage his cassock, and certainly don’t slice him; bring him back intact, clean, and unharmed. Now, repeat it back to me.’ This granularity of information transmission is the cornerstone of industrial-grade reliability.”
The aforementioned technology has been validated in several high-difficulty scenarios. In dexterous manipulation tasks, TermiTech’s “Piano Master” integrates spatial understanding and tactile feedback, achieving millisecond-level precise control and fusion of long- and short-term memory, significantly enhancing expressive capability. It stood out from 53 teams to win an award at the 2025 Shenzhen Dexterous Hand Competition and shone at the opening ceremony of AWE2026. In another scenario, “Unmanned Aircraft Cockpit Testing,” through VTLA multimodal visual-tactile fusion and encoding of human knowledge and procedures, airworthiness regulations were transformed into learnable constraints, achieving a 25% improvement in testing efficiency and a 20% increase in operational accuracy under the same procedures.

IV. Commercial Moat: Full-Stack Implementation and a Team Forged Over a Decade
Only implementable intelligence has vitality.
TermiTech has launched a complete product matrix covering everything from perception to execution:
Brain Center — TermiBrain Series:
TermiBrain-R, an embodied brain for highly interactive fine-grained operations; TermiBrain-G, an embodied brain for multi-agent swarm control;
Collaboration Platform — TermiMaster, a multi-machine heterogeneous unified scheduling and air-ground collaborative robot management system:
Currently, TermiMaster has integrated and managed over 20 mainstream embodied hardware types, breaking down operational barriers between various robots, robotic dogs, drones, and industrial robotic arms. It has achieved centralized decision-making and business closed loops in high-value scenarios such as 3C manufacturing, industrial inspection, exhibition education, and urban patrol. It truly realizes “one brain managing multiple machines, one screen overseeing the entire situation.”
Core Body — TermiBot:
TermiBot focuses on dexterous manipulation. The embodied brain handles long-term planning and continuous iteration of complex tasks, paired with a high-degree-of-freedom dexterous hand capable of executing complex, fine-grained human action sequences. This is the physical foundation enabling ultra-fine tasks like playing the piano.
Additionally, TermiBot natively supports VLA (Vision-Language-Action) and portable UMI (Universal Manipulation Interface) data fine-tuning. This allows robots to quickly learn new skills through human demonstrations using simple data collection devices, and the collected visual, force, and pose data can be directly fed back into the model training pipeline without complex format conversion.
Circulating Blood — TermiDataClaw.
TermiDataClaw is a task-driven embodied data closed-loop system. It completely changes the old paradigm of organizing data “by device or by sensor,” instead adopting “task as the smallest organizational unit,” allowing collection, quality control, and model training to all revolve around specific operational task closed loops. Its core capabilities can be summarized in six keywords: What You See Is What You Get—collected data, processed through a standardized pipeline, can directly enter the training and optimization process; Multimodal Alignment—integrates multimodal data such as vision, voice, force, pose, and trajectory, unified into task-level expressions; Intelligent Processing—supports slicing, annotation, quality inspection, error data return, and high-value sample screening; Agent-based Full-Chain Closed Loop—from data collection to model evaluation to strategy updates, all automated; and most critically, the Data Flywheel—based on model performance and real operational feedback, it automatically identifies capability gaps, reversely drives data supplementation and strategy optimization, allowing the model and robot capabilities to continuously evolve with every real interaction.
It is this “Brain-Platform-Body-Data Blood” four-in-one product architecture that gives TermiTech’s embodied intelligence truly implementable, replicable, and evolving vitality.
Behind this composed implementation is a team with over 10 years of experience in AI and large model productization. Core members come from leading companies like Huawei and have led the development of multiple vertical domain large models, including communication O&M large models, medical large models, and domestic database large models, as well as the planning and implementation of over 100 AI applications. They possess a complete understanding from training thousand-card cluster, billion-parameter models to delivering industry scenarios. Just months after official operations, the company has already secured over 30 million RMB in intended orders and generated over 3 million RMB in revenue, with the commercial flywheel accelerating.
The launch of TermiBrain GCWM1 marks TermiTech’s transition from ‘letting robots see’ to ‘letting robots think through,’ from rigid imitation to autonomous decision-making. At the twilight of dawn and dusk, intelligence awakens.
