
BeijingMay 6, 2026 /PRNewswire/ — Ipsos, a global leading market research company, recently unveiled a synthetic data augmentation technology solution. Developed in collaboration with Stanford University, it features a proprietary tabular diffusion model and the SURE four-dimensional evaluation framework. This helps brands obtain reliable data insights and drive smarter business decisions, even in scenarios with insufficient sample sizes or scarce data on specific subgroups.
Simply put, synthetic data augmentation involves learning the underlying patterns of original data to generate new “virtual samples,” thereby expanding data volume and enhancing analytical capabilities. This technology is becoming a vital component of Ipsos’ market research practices—especially in situations where sample sizes are inadequate or subgroup data is scarce.
An apt analogy: A student receives a study guide from an unknown source. They don’t know if the content is accurate (quality untested) or what the specific exam questions will be (specific application scenario), yet they claim, “This guide will improve my grades by 10%”—sounds absurd, doesn’t it?
More notably: If synthetic data is simply treated as equivalent to real, independent samples for statistical testing (known in the industry as “naive testing“), the error rate could be as high as 75%-80%. This means brands have a high probability of making wrong decisions based on false “significant conclusions“, with potential losses far exceeding the research costs saved.
Ipsos’ Three Core Capabilities Build a Technological Moat
1. Exclusive Tabular Diffusion Model: At the Forefront of Academia
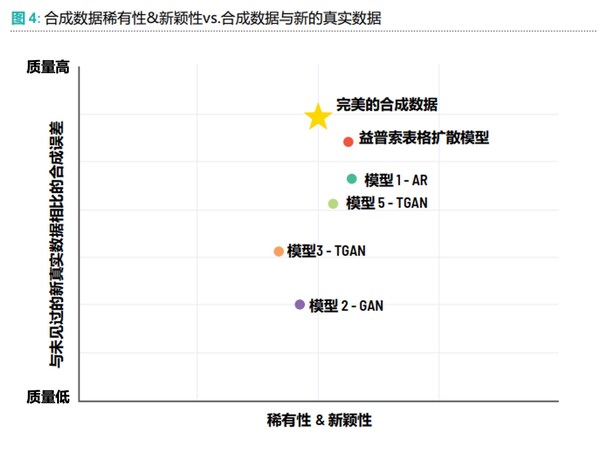
Traditional synthetic data often uses Generative Adversarial Networks (GANs), but these have significant limitations when handling complex tabular market research data.
Ipsos, in partnership with industry and academic collaborators—including an ongoing collaboration with Stanford University—has developed a new technology better suited for market research data: the Ipsos Tabular Diffusion Model. Simultaneously, we have built the SURE four-dimensional integrity framework for evaluating data quality and created the Ipsos Synthetic Data Workbench, enabling these methods to be applied in daily operations and standardizing and productizing data augmentation capabilities.
Ipsos’ test results show that synthetic samples generated using this model are more realistic, reliable, and representative, preserving the overall trends of real data while effectively replicating rare distribution characteristics of samples.
2. SURE Four-Dimensional Evaluation Framework: Evidence-Based at Every Step
It’s not enough for synthetic data to simply “look like” real data; it must demonstrate value in practical applications. Ipsos’ proprietary SURE four-dimensional evaluation framework systematically assesses data from the following core dimensions:
S — Statistical Similarity
Is the synthetic data statistically faithful to the original real data? We employ a range of techniques, including Jensen-Shannon divergence, Principal Component Analysis (PCA), and Kernel Density Estimation (KDE), to conduct multi-level comparative verification from global and key decision-making dimensions. High fidelity means: if the original real data exhibits a certain pattern, the synthetic data will capture that pattern as well.
U — Utility
Is the synthetic data truly useful? Based on statistical principles, we use mathematical formulas to calculate how much information the real dataset contains, then measure how much genuinely new, useful information our generated synthetic data adds. We also use Equivalent Sample Size (ESS) assessment to ensure the correctness of statistical inference. This step is crucial: it can identify synthetic data that “looks good” but contains very little information, preventing brands from making wrong decisions based on false significance.
R — Rarity & Novelty
The core value of synthetic data lies in “generating new combinations that exist in reality but are not covered by the sample,” rather than simply replicating existing samples. We quantify the information expansion scope of synthetic data through methods like inter-sample distance analysis, nearest-neighbor redundancy checks, and coverage metrics. Diversity is quantified using distribution entropy and latent space dispersion, ensuring the model generates an extension of reality, not a mere copy.
E — Expert Validation
Even if all statistical indicators pass, synthetic data still requires “human inspection” by domain experts. Experts judge whether the data and the insights derived from it are credible, reasonable, and actionable in the real world. This step represents human wisdom that machines cannot replace, ensuring synthetic data passes the test of the real world.

3. Professional Synthetic Data Workbench: The Perfect Combination of Standardization and Productization
To ensure the quality and stability of data synthesis, Ipsos has independently developed the Ipsos Synthetic Data Workbench, deeply integrating cutting-edge technology with standardized processes.
Core features include:
- Proprietary generation methods designed for structured questionnaire formats
- Advanced technology capable of integrating multi-source related datasets
- Lightweight, fast-learning models suitable for small samples
- Universal imputation solutions ensuring output self-consistency
Additionally, the workbench includes a complete data cleaning and optimization toolkit, covering variable format standardization, logical contradiction correction, outlier handling, subgroup balance weighting, and feature optimization, ensuring the dataset used for training models has the best structure and strongest representativeness.
“We don’t make vague promises about effectiveness. Synthetic data isn’t a panacea, but it is powerful when used correctly. Our responsibility is to help clients clarify when synthetic data truly adds value and when it offers no benefit. This is being accountable to our clients and to the industry.“
Synthetic Data Augmentation: Prudent, Transparent, and Evidence-Based
Through long-term practice, Ipsos has summarized the following key conclusions:
Regarding Training Data Volume:
Regarding Effective Sample Size:
With 1,000 real samples plus 500 synthetic samples, the effective sample size is not 1,500, but somewhere between 1,000 and 1,500. This is because synthetic data violates the premise of “independent, equal-probability sampling” required by traditional statistical tests; each synthetic sample originates from a model trained on the original data, not from a completely independent observation.
In its practical synthetic data operations, Ipsos follows these four steps, integrated with the SURE framework:
01 Data Assessment — Is this data suitable for synthesis? Before modeling, evaluate the data’s suitability, quality, and representativeness.
02 Data Preparation — Clean, align, optimize. Standardize data formats, resolve inconsistencies, and ensure the data is in a state ready for direct modeling.
03 Data Modeling and Generation. Apply diffusion models and data augmentation algorithms that meet SURE standards.
04 Data Validation and Integrity Check. Test the synthetic data output against the fidelity, utility, and risk criteria of the SURE framework to confirm its robustness.
Ipsos advocates for a unique fusion of Human Intelligence (HI) and Artificial Intelligence (AI) to drive innovation and provide clients with impactful, human-centric insights. This philosophy is deeply embedded in all its AI solutions, including synthetic data augmentation technology. Through the organic integration of HI and AI, Ipsos delivers safer, faster, and contextually grounded deep insights, creating relevance and value for its clients.
