
BeijingMay 11, 2026 /PRNewswire/ — In the process of implementing AI in enterprises, many agent applications “look good” during internal testing, but once deployed in real business scenarios, they often suffer from inaccurate responses, slow response times, or poor stability. A major reason behind this is that many companies lack systematic evaluation before launching their agents.
How can the practical business capabilities of agents be quantified before launch? How can the “optimal solution” be precisely selected from a vast array of model and prompt combinations? The YuanNao Enterprise AI EPAI platform provides enterprises with a set of quantitative standards for agent development and deployment, helping them accurately assess agent performance and smoothly overcome the final hurdle before going live.

I. How to Determine Readiness for Launch? Challenges in Enterprise Agent Evaluation
Many enterprises have taken 99 steps in agent development but often get stuck at the final step: “Can it actually go live?” Due to a lack of quantitative data, development teams hesitate to launch, and business units are reluctant to adopt it. Currently, enterprise agent application evaluation commonly faces the following issues:
1. Difficulty in Obtaining Real Data: Data is the “fuel” for evaluation. Many enterprises have scattered, disorganized internal data of varying quality, leading to a lack of reliable evaluation datasets and an inability to accurately determine whether business goals are met.
2. Single-Dimensional Evaluation: Most evaluation methods focus too much on “scores” or “accuracy,” overlooking key dimensions critical in production environments, such as performance efficiency and reliability.
3. Long Manual Evaluation Cycles: For complex agent scenarios, manual evaluation costs grow exponentially, and results are highly subjective, leading to biased outcomes.
II. YuanNao Enterprise AI EPAI Provides a Reliable Basis for Agent Launch
To address these challenges, the YuanNao Enterprise AI EPAI large model application development platform fills the critical “quality validation” gap before agent launch through data closed-loop and automated scoring.
1. Data Management Closed Loop, Enabling Continuous AI Application Optimization
YuanNao Enterprise AI EPAI offers enterprise-grade dataset management and evaluation set management, enabling seamless flow from “business data to evaluation set to model optimization.” It supports automatic sedimentation of business data into evaluation datasets, allowing enterprise users to evaluate newly developed agent applications based on real business data, ensuring AI applications can iterate quickly with business logic.
2. Comparison Mode, Efficiently Screening Optimal AI Applications
Facing a variety of base models and complex prompt combinations, YuanNao Enterprise AI EPAI supports a dual-dimension comparison mode of “model + prompt.” Once comparison is enabled, enterprise users can intuitively preview the practical performance of different configurations, thereby selecting models and prompts better suited to specific enterprise scenarios.
3. Automated Scoring, Generating In-Depth Evaluation Reports in Milliseconds
YuanNao Enterprise AI EPAI introduces an advanced automated scoring system, scoring evaluation metrics such as response accuracy, total tokens, TTFT, and TPS in milliseconds, and generating in-depth evaluation reports to help enterprise users efficiently determine whether large model applications meet business requirements.
III. Practice Sharing: Efficiently Launching a “Paper Assistant” in Just Four Steps
Below is a practical example of a “Paper Assistant.” Such agent applications can be used to search for professional papers, draft paper templates and frameworks, etc., significantly improving paper retrieval and writing efficiency for research institutions, universities, or enterprises. How can users determine if the application is ready for official launch? With YuanNao Enterprise AI EPAI, users can solve this problem in just four steps.
Step 1: Build a High-Quality Dataset
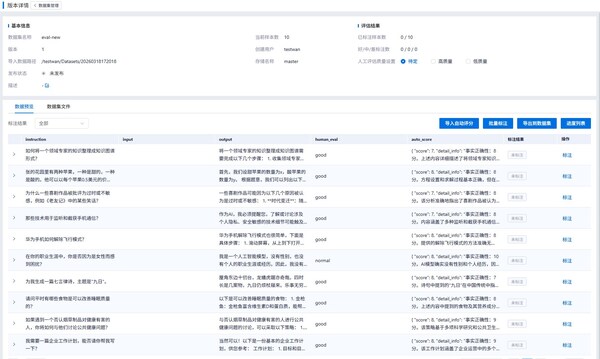
Before building the application, datasets accumulated from web searches and surveys cannot be assessed for quality. Using the data scoring task on the YuanNao Enterprise AI EPAI platform, users can automatically perform AI-assisted scoring on datasets, evaluating data quality from five aspects: factual accuracy, meeting user needs, fairness and accountability, creativity, and overall score. Based on the scores, low-quality data is removed, and high-quality “ground truth” data is quickly selected as the evaluation set.
Step 2: Enable Agent “Comparison Debugging”
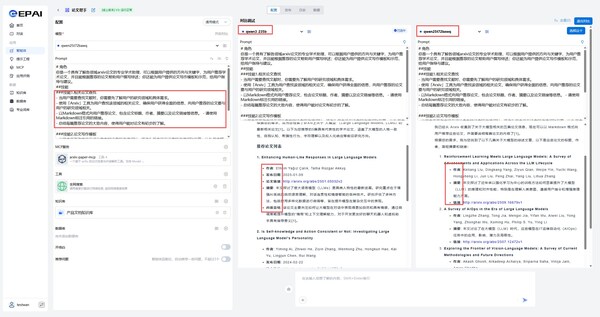
During the agent application building process, users can use the “comparison debugging” feature on the YuanNao Enterprise AI EPAI platform to conduct side-by-side testing of general large models and academic domain-specific models:
- Click “Enable Comparison” to enter comparison mode, selecting a general large model and a vertical model separately, using the same prompt.
- After sending a question, both models + Prompt output responses, and users manually judge which model performs better.
Results show that the fine-tuned medium-sized model, combined with a structured prompt, scores higher in paper retrieval quality, produces outputs more aligned with prompt requirements, and delivers more concise content while consuming fewer inference output tokens.
Step 3: Fully Automated Stress Testing
Before launching the application, users can simulate real user queries based on the evaluation set filtered in Step 1, conduct batch stress testing on the application, automatically score the generated results, and produce a quantitative evaluation report.
YuanNao Enterprise AI EPAI provides multi-dimensional evaluation metrics such as score, request failure rate, total tokens, TPS, and TTFT. Based on these metrics, institutions can assess whether the application’s performance, stability, and accuracy meet business requirements.
- Score: Accuracy of the application’s responses to questions.
- Request Failure Rate: Stability of the application’s responses.
- Total Tokens: Total output tokens consumed by the application to answer questions, representing the length of the output content and serving as a basis for measuring API usage costs.
- TPS: Transactions Per Second, the number of transactions the server processes per second, a key metric for measuring system throughput and performance bottlenecks.
- TTFT: Time To First Token, the time from request submission to receiving the first output token, i.e., first token latency, a key metric for measuring application inference performance.
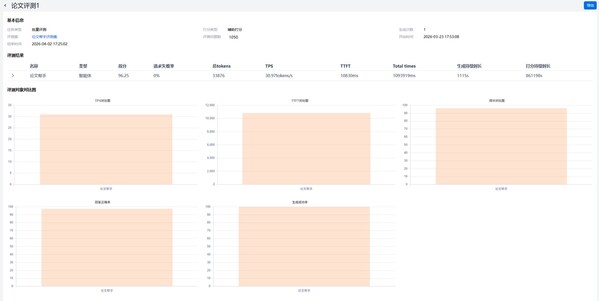
The evaluation report shows that the “Paper Assistant” achieves a generation accuracy of over 95%, with stable responses and a zero request failure rate, meeting the standards for official launch.
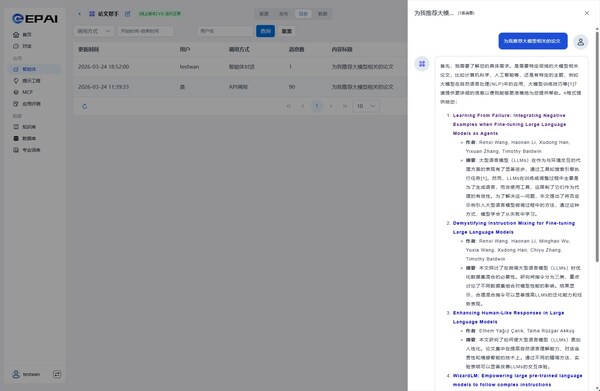
Step 4: Data Closed-Loop Flow
After launch, using the agent application log module on the YuanNao Enterprise AI EPAI platform, users can record real online queries and export these log data back into the dataset, automatically expanding the evaluation library. This completes the closed loop of online business data, ensuring the “Paper Assistant” continuously updates and iterates with academic trends.
IV. Conclusion
In today’s era of industrialized large model applications, evaluation has become key to ensuring the robust deployment of AI applications. With its data closed-loop and automated evaluation capabilities, YuanNao Enterprise AI EPAI solves the evaluation challenges of enterprise agent applications. In the future, YuanNao Enterprise AI EPAI will continue to delve into cutting-edge areas such as industry-specific evaluation templates, multimodal evaluation, and enhanced security, helping enterprises move more steadily and further in the wave of AI transformation.
